
Medical records just became the hottest commodity in Silicon Valley. In a stunning 72-hour span this January, OpenAI and Anthropic launched competing platforms that transform fragmented health data into AI-powered personal health advisors, signaling a digital colonization of America’s healthcare system. While regulators spent a decade mandating interoperability through the 21st Century Cures Act, tech giants are exploiting the resulting data floodgates, deploying sophisticated language models to ingest, analyze, and monetize patient information at unprecedented scale.
Have we traded medical privacy for the convenience of conversational health intelligence?
On January 7–8, 2026, OpenAI launched two new products: – ChatGPT Health – for general public, allowing connecting to medical records and wellness apps; and OpenAI for Healthcare, a HIPAA-compliant suite powered by GPT-5.2, which is already deployed across leading health systems including Stanford Medicine.
Just three days later, Anthropic announced a partnership with HealthEx, making it possible for Claude users to connect their personal health records from over 50,000 provider organizations and receive AI-powered responses to their health questions, grounded in their actual medical data. That moves the industry from competitive jostling for health data into gold rush territory.
The Regulatory Revolution: From Data Silos to Mandated Interoperability
The turning point actually came much earlier – with the 21st Century Cures Act, signed into law in December 2016, with enforcement beginning in April 2021. The law’s most powerful provision prohibits “information blocking” — the practice of interfering with the access, exchange, or use of electronic health information. It mandated that healthcare providers and electronic health record (EHR) vendors implement APIs and data standards to enable data exchange between authorized entities.
The Cures Act sets the legislative foundation, but what about infrastructure? In late 2023, the Office of the National Coordinator for Health Information Technology launched the Trusted Exchange Framework and Common Agreement (TEFCA), establishing a national governance structure for health information exchange. TEFCA creates a common agreement framework for regional, state, and local Health Information Organizations (HIOs) to participate in nationwide exchange networks. This represents the most ambitious attempt to create a unified health data ecosystem in the United States.
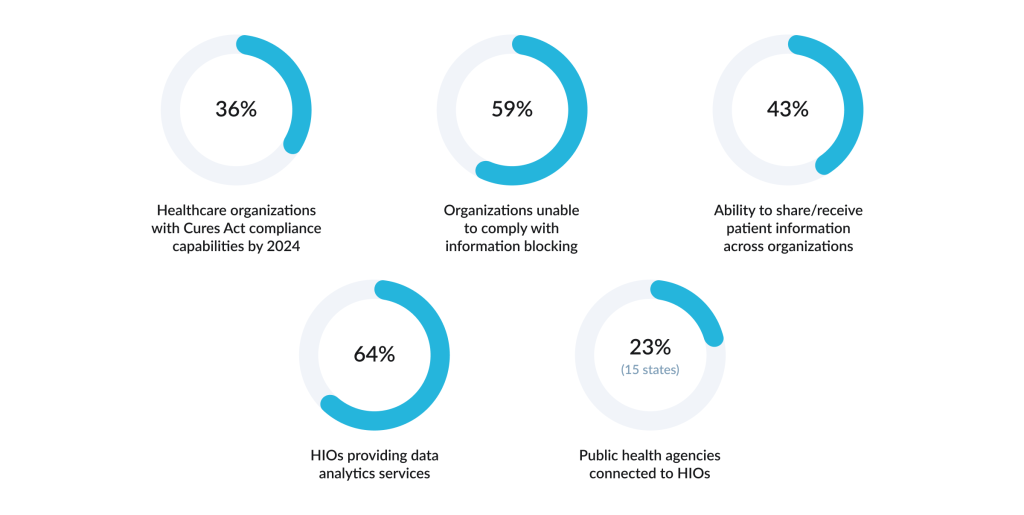
Easier said than done — a great share of organizations are still unprepared to free information flow. As of 2024, 61% of healthcare organizations have invested in upgrades, while only 36% had actually implemented the necessary capabilities to comply with requirements. More than half (59%) of healthcare organizations reported an inability to comply with the information blocking rules, and 57% could not share or receive patient-level information with other organizations.
In some areas and organizations it actually worked. A study by Jordan R. Pollock and colleagues found that before the implementation of the Act, radiology reports became available for patients in specialized portals after a 36-hour delay. Post-enforcement, that window reduced to just 0.4 hours — almost immediate access for patients upon finalization.
Improvements are not universal across the whole healthcare system; to date one of the most widespread means of communication between different healthcare establishments remains the fax.
The Interoperability Challenge: Standards Proliferate, Data Remains Fragmented
Interoperability, the ability of different health IT systems to exchange and use data seamlessly, remains the fundamental technical challenge.
Real-world examples demonstrate both the potential and the current limitations of interoperability when properly implemented. For example, Maryland’s health information organization successfully linked COVID-19 laboratory reports into its contact tracing system to support rapid outbreak contact tracing and epidemiological investigations during the pandemic. It eliminated the necessity to manually re-enter lab results across multiple systems, enabling state health officials to identify clusters and trace contacts within hours instead of days.
Again, such cases are not systematic, and while 94% of U.S. hospitals have adopted certified EHR technology, the majority of healthcare data generated still goes unused for clinical decision-making, locked away in incompatible systems that speak different digital languages.
At the technical level, the healthcare system relies on multiple overlapping standards, like HL7 FHIR, DICOM for imaging, OMOP-CDM for clinical data models, and various specifications. For example, while DICOM has been ubiquitously adopted for medical imaging, the standard lacks the standardized metadata necessary to identify and semantically link relevant images, forcing organizations to develop proprietary metadata solutions.
Beyond technical standards, organizational and workforce barriers impede progress. Funding constraints plague many systems — 32% of healthcare information exchange organizations cite limited funding as a significant barrier.
Healthcare organizations further report competing organizational priorities, insufficient staffing, and inadequate technical capacity to process incoming data from partner organizations.
When hospital executives were surveyed, 57% of them expressed the opinion that data-matching errors will precipitate a healthcare crisis within the next 5 to 10 years, as increased data volumes exacerbate existing fragmentation without corresponding advances in master data management and patient identity resolution technologies.
This all creates the impression that technologies and solutions are piling up, yet we still cannot achieve meaningful progress — we have built systems so complex that advancement itself has stalled.
Against this backdrop, tech giants are rolling out solutions that propose workarounds to challenges, striving to make sense of scattered health data. Solutions are promising and daring; however, there are clear signs that these solutions break existing rules. Maybe it is time to do so, or maybe we are sacrificing safety for speed. Have we broken bad?
The Tech Giants’ Play: OpenAI and Anthropic
Consider the tempo of recent announcements. On January 7, 2026, OpenAI launched ChatGPT Health, enabling consumers to upload their medical records and wellness data directly into the chatbot. A day later, the company unveiled OpenAI for Healthcare, an enterprise suite deployed across institutions including Stanford Medicine and Boston Children’s Hospital.
On January 11, 2026 Anthropic announced a partnership with HealthEx, allowing Claude users to connect their comprehensive medical histories from over 50,000 provider organizations and receive personalized health insights through natural language conversations.
Within days the world’s most sophisticated AI firms signalled that they had placed patient health data at the center of their consumer and enterprise offerings. HealthEx’s CEO Dr. Priyanka Agarwal articulated: patients “struggle to understand their own health because of how challenging the healthcare system can be to navigate.” OpenAI and Anthropic’s solutions directly address this by personalized health intelligence anchored in an individual’s own medical reality.
This addresses the exact pain points described earlier, promising to unify fragmented records, empower patients to understand their health, and equip caregivers with AI-powered tools.
Yet it becomes clear that existing oversight frameworks are ineffective to govern the speed at which these technologies are deployed. On January 6, 2026, the FDA issued revised guidance on Clinical Decision Support Software. The guidance explicitly addresses software for healthcare professionals, while for patient-directed recommendations, the regulatory pathway is less clearly defined.
However, in reality, ChatGPT Health allows users to upload lab results, ask the system to interpret genetic data, and receive summaries of imaging findings — capabilities squarely within the FDA’s definition of patient-directed medical recommendations. HealthEx’s integration with Claude explicitly enables users to receive “personalized health summaries, lab result explanations, and record-based insights.” The January 2026 FDA guidance creates ambiguity about patient-directed medical AI recommendations. OpenAI and Anthropic appear to interpret their patient-facing tools as outside device regulation, while critics argue the guidance’s flexibility was not intended to enable unregulated health recommendations to consumers.
Why the urgency? Why now?
Health data represents a unique resource: it’s detailed, continuous, longitudinal, and contains sophisticated medical concepts. An LLM trained on millions of patient records can develop advanced clinical reasoning capabilities.
Several forces converged in January 2026: legal mandates for health data interoperability finally created systematic API access to patient records nationwide; GPT-5 showed good enough performance on medical benchmarks, providing credible justification for rapid deployment; and mature healthcare API infrastructure meant companies could scale without technical barriers.
Companies deploying immediately after the FDA issued guidance are using the regulatory lag and liability ambiguity, betting they can establish market dominance before comprehensive oversight arrives.
Digital colonization
Tech firms leverage health data to create advantages, serving as an indispensable middleman for patient-provider data exchange. A relatively new term has arisen in academic research — “digital colonization,” — a four-stage mechanism by which technology giants enter highly regulated industries without providing the core services those industries depend on.
– First, they capture data through direct means – consumer apps, wearables, patient portals or indirectly through partnerships with existing healthcare providers and insurers;
– Second, they combine this data with their AI and machine learning capabilities to generate insights that healthcare incumbents cannot match;
– Third, they offer these insights and data infrastructure services — particularly cloud storage back to hospitals and health systems, making themselves essential;
– Fourth, they avoid the burdensome licensing and regulatory oversight that traditional healthcare providers face by positioning themselves as technology vendors rather than healthcare providers, while simultaneously becoming central to how healthcare operates.
This strategy allows Big Tech firms to achieve dominance in healthcare without the costs, liabilities, and regulations that come with actually treating patients. As the study noted, they “become core actors in these industries while escaping conventional sectoral regulation.”
Consider the infrastructure layer. Amazon, Microsoft, and Google collectively control 65% of the global cloud storage market. In the Netherlands, an estimated three-quarters of all general practitioner records are stored on Amazon servers, while France’s Health Data Hub relies on Microsoft. As healthcare becomes increasingly digitized and cloud-dependent — accelerated by regulatory mandates for data interoperability — these technology companies are becoming unavoidable players.
Safety and Security Risks
– The explosion of data exchange creates new security and privacy challenges: 99% of healthcare organizations experienced an API security incident in the past 12 months, with API vulnerabilities accounting for the largest increase in attack incidence of any industry. Because the Cures Act mandated data interoperability, thousands of custom APIs were built to connect incompatible legacy systems. In security testing, researchers accessed more than four million patient and clinician records using a single patient login, and more than half of tested mobile health applications contained hardcoded API keys that would allow attackers trivial access.
This vulnerability multiplies as AI companies build new layers of integration. OpenAI for Healthcare and Claude for Healthcare both require APIs connecting to fragmented EHR systems to ingest raw patient data. Each new integration point — diagnostic algorithms, cloud training environments, third-party vendor access — represents a breach vector.
– Hallucination, data poisoning, and medical misinformation at scale.
The competitive urgency driving deployment has also meant insufficient testing for a fundamental AI vulnerability: hallucination — the phenomenon where language models confidently generate fabricated or misapplied medical information. A 2026 meta-analysis of oncology AI responses across 39 studies and 6,523 model outputs found that hallucination rates vary significantly by model and prompt type, with patient-oriented queries showing particularly high error rates. Studies repeatedly show that ChatGPT exhibits high (23% in the cited study with structured prompting and temperature optimization) hallucination rates, — while Google’s AI Overviews produce documented accuracy problems in 44% of medical search results.
– Data quality, reidentification, and the illusion of anonymization
Patient-provided health records often contain transcription errors, lab values without reference ranges, and imaging impressions using nonstandard terminology. Much of the data ingested by OpenAI and Anthropic through provider API integrations has never been formally “validated” in the clinical sense — it is simply the lived reality of fragmented EHR systems. The FDA guidance explicitly states that CDS software relying on “nonvalidated data” remains subject to FDA oversight and device classification, but this is not happening.
Additionally, the promise of deidentification has proved insufficient. While removing direct identifiers like names and dates reduces reidentification risk, complete anonymization remains nearly impossible in clinical settings, and individuals can sometimes be recognized through combinations of diagnoses, treatment dates, and other quasi-identifiers.
– The regulatory and liability vacuum
Compounding these technical risks is a fundamental legal ambiguity. OpenAI and Anthropic, through their Business Associate Agreements, claim to be HIPAA-compliant vendors. But when patients upload medical records directly to ChatGPT Health or Claude for Healthcare, the patient — not a covered healthcare entity — is the user, placing the interaction partially or fully outside HIPAA jurisdiction. Multiple state-level privacy laws — e.g., Washington’s “My Health My Data Act” — may apply, but enforcement is nascent and regulatory clarity nonexistent.
Regulatory Arbitrage at Patients’ Expense
The simultaneous deployment of ChatGPT Health, Claude for Healthcare, and competing systems represents a strategic move to establish market dominance before regulators could establish comprehensive oversight. The companies have moved rapidly from research to deployment, treating patient-facing medical AI as a natural extension of consumer chatbot capabilities. They have built systems, connected data, launched to millions of users and the regulatory framework has not caught up.
Tech companies exploit gaps in FDA authority, which traditionally targets medical device manufacturers, HIPAA jurisdiction, which doesn’t clearly cover consumer AI, and liability law, which is silent on AI-generated medical advice.
The competitive gold rush for health data has created a system where technological speed vastly exceeds governance capacity.
None of this criticism implies that these platforms lack value or that fragmented data should remain unintegrated. But for now it is unclear how to balance the interests of patients and, society with the breakneck speed of those innovations.